什么是Rendering Path
它是渲染目标使用的光照流程,也就是渲染管线中光照实现的方式。
Unity目前有前向(Forward),延迟(Deferred)和Forward+这几种渲染路径(Rendering Path),更早之前还有顶点照明渲染路径(Vertex Lit Rendering Path)。
Forward
我们进行移动平台游戏开发通常会采用前向渲染。户外的场景,一般因为有一个主光源(平行光),总体光源数不多,可以采用Forward的方式。多光源的场景(比如室内,洞穴,深空这种背景较暗的场景)则采用光照烘焙的方式,因为Forward对Lights数量非常敏感,存在多光源累加计算问题。所以这也是为什么要讨论Deferred和Forward+的原因。
Deferred
延迟渲染是主机平台的主流技术,移动平台目前使用的比较少,主要还是因为带宽的问题,而带宽是导致手机功耗问题的主要原因。我们熟知的原神使用了延迟渲染,必然带来的问题是设备覆盖率的偏低,对于大多数项目来说不具有普适性。
Forward+
Unity2022LTS版本URP管线已经正式支持(Forward+ Renderer Support – Unity Platform)。

Forward+ Rendering Path | Universal RP | 14.0.8 (unity3d.com)
- Forward+结合了Forward和Deferred的优点:无G-buffer,支持复杂材质。
- Forward Per-Object有Max8个光源的限制(我们一般会设置为4,再多的收益递减),Forward+没有这个限制。
- 当然它还是有一些限制,Per-Camera对Lights的限制:PC和Console平台是256,Mobile平台是32。
渲染指令序列
我们通过Unity Frame Debugger(Built-In管线),来看看不同渲染路径的绘制过程。
Forward
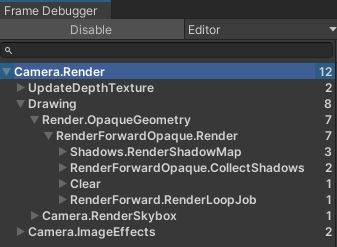
基本思想是依次遍历场景中的每个物体,将所有光源对它的影响考虑在内,计算光照结果并渲染该物体,符合直觉,受到广泛硬件支持。
Deferred
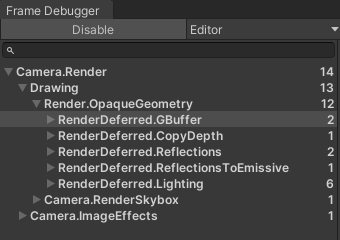
对比Forward,一个明显区别就是Deferred创建了一个G-Buffer的对象(后面会提到),把光照计算与几何信息处理分为两个阶段,而不是逐Object,使得场景内物体的数量与光源的数量解耦。
光照计算量
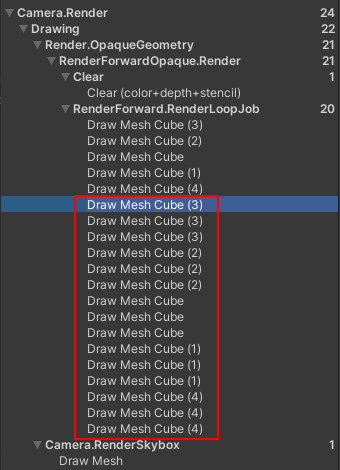
我们来测试一下多个物体被多个光源影响下的计算量(Pass),以下案例为5个不透明Cube被3个聚光灯照射的情景。
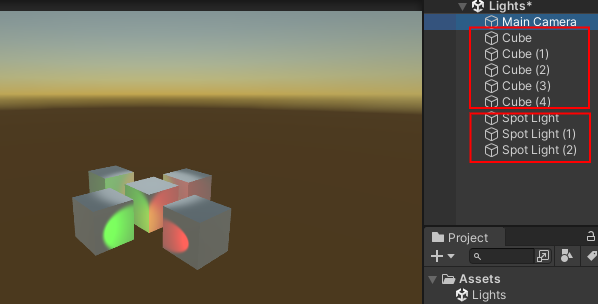
Forward
每个物体按照接受到的每个光源独立的渲染一遍。所以M个物体,受N个光源的影响,则需要的渲染Pass数量为:物体5 + 物体5 x Lights3 = 20次,复杂度为O(M*N)。
另外带来的Overdraw计算问题可能会很严重:
- 一个物体受场景中多个光源的影响,对应的像素点可能被重复绘制多次,而我们最终看到的是最后一次的结果,这就意味着之前的计算都在做无用功。
- 由于先Lighting,再做深度测试。对于那些部分或完全被另一些物体遮挡的、实际上不可见的物体,这部分像素进行的光照计算也等于浪费。
Deferred
首先将物体的几何信息(位置、法线、颜色、镜面值)存到G-Buffer(Geometric Buffer)中,然后在光照处理阶段,使用G-Buffer中的纹理数据,对每个片段进行光照计算。这样将本来在物体空间(三维空间)进行光照计算放到了屏幕空间(二维空间)进行处理。由于光照计算时已经包含了深度测试,所以缓冲区中的像素信息,最终都会呈现在屏幕上,不存在冗余。这就保证了在计算光照时,每个像素都只被处理一次,避免了不必要的开销。
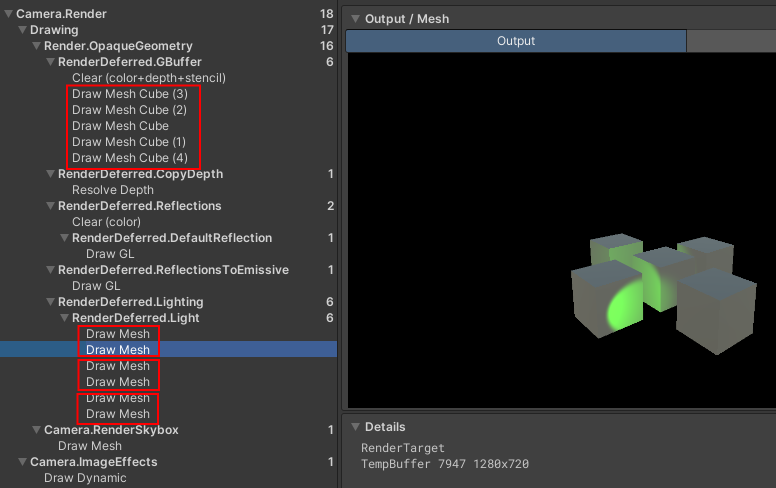
这里是逐光源Lighting Pass。每个光源2个Pass,第一个Pass画一个灯光的Volume Mesh,用Stencil标记范围,第二个Pass做Ligting,所以计算量是:物体5 + 2 x Lights3 = 11次,复杂度为O(M+N)。
Deferred的局限性
主要是内存开销大,读写G-buffer的内存带宽用量是性能瓶颈,而移动端功耗是一个非常热点的问题。
其他方面:
- 只能用来绘制Opaque的物体
- G-buffer只是记录当前能看到的像素,而半透明物体,同一个像素点,需要记录更多信息来做Blending,这显然会加重对带宽的要求,所以不做记录。
- 半透明物体依然走Forward的流程(当然半透明物体是否受光照影响,可以根据具体对象的材质来决定)。
- 只能使用同一个材质,即同一种光照Pass
- 道理很简单,G-buffer并不知道哪个像素点,属于哪个Mesh。
- 但是一个场景的光照算法本来就应该是统一的,不一样的反而是少数,从这一点上来说是顺应设计需求的。
- 对多重采样抗锯齿(MSAA)处理的支持不友好
- 可以用FXAA等方案。
更多细节比较
| 延迟 | 前向 | |
|---|---|---|
| 功能 | ||
| 每像素光照(法线贴图、光照剪影) | 是 | 是 |
| 实时阴影 | 是 | 带有警告 |
| 反射探针 | 是 | 是 |
| 深度和法线缓冲区 | 是 | 其他渲染pass |
| 软粒子 | 是 | – |
| 半透明对象 | – | 是 |
| 抗锯齿 | – | 是 |
| 光照剔除遮罩 | 受限 | 是 |
| 光照保真度 | 全部每像素 | 部分每像素 |
| 性能 | ||
| 每像素光照的成本 | 照射像素数量 | 像素数量 * 照射对象数量 |
| 正常渲染对象的次数 | 1 | 每像素光照的数量 |
| 简单场景的开销 | 高 | 无 |
| 平台支持 | ||
| PC (Windows/Mac) | Shader Model 3.0+ 和 MRT | 所有 |
| 移动端 (iOS/Android) | OpenGL ES 3.0 & MRT, Metal | 所有 |
| 游戏主机 | XB1、PS4 | 所有 |
MRT机制
在介绍G-buffer之前先介绍一下MRT机制。
MRT,Multiple Render Targets的缩写,是OpenGL ES 3.0新特性,它允许应用程序一次(一个Pass)渲染到多个缓冲区(或多张RT中),需要GPU支持。
在图形图像算法中比较常用,主要用于获取算法中间结果、底图或者Mask ,也用于多种高级渲染算法中,例如延迟着色和快速环境遮蔽估算。
通过SystemInfo.supportedRenderTargetCount(只读),可以知道支持多少个同时渲染目标(MRT)。
设置当前渲染目标Graphics.SetRenderTarget的重载形式public static void SetRenderTarget (RenderBuffer[] colorBuffers, RenderBuffer depthBuffer),使用colorBuffers 数组,即启用了使用多渲染目标 (MRT) 的技术,其中片元着色器可以输出多种最终颜色,可以用于保存RGBA颜色、法线、深度信息或者纹理坐标,每个颜色连接一个颜色缓冲区。
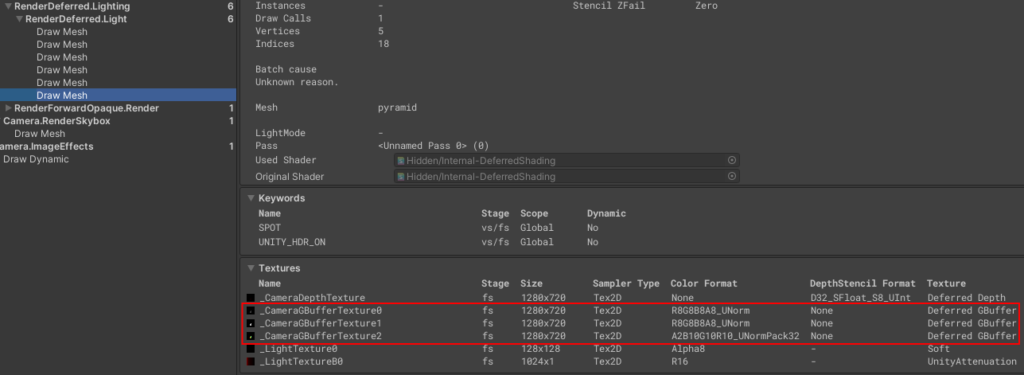
G-buffer
前面说到,Deferred渲染最重要一个特征就是使用了G-buffer。它本质上是一个帧缓存,几何阶段用来保存数据缓存的统称(包含各种计算光照需要的表面信息),并在后面光照处理阶段中使用的一组纹理。这么多信息在一个Pass中同时处理保存到多张RT中,正是基于MRT机制。
Unity官方的Layout图如下:

以下为光照计算需要的信息,存储在G-buffer的3张RT中。
Micro G-buffer
一种压缩G-buffer的方案,节省填充率和带宽,详细介绍可以参考 Unity URP+Micro Gbuffer自定义延迟管线 – WalkingFat。