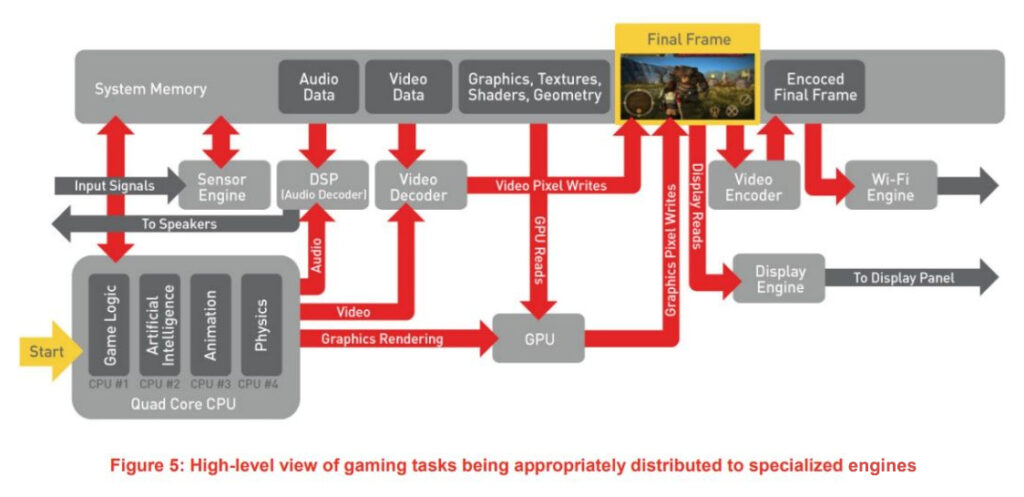
图形系统作为游戏引擎的核心系统之一,为了实现特定的渲染效果以及保证良好的性能,我们需要对这部分知识进行系统性的掌握。这里从计算机图形显示的整个流程出发来理解上屏,渲染的对象,效果呈现以及渲染流程等内容,这样比较容易和生活实践联系起来,有利于理解知识点在其应用领域中所处的位置,从而形成画面感。
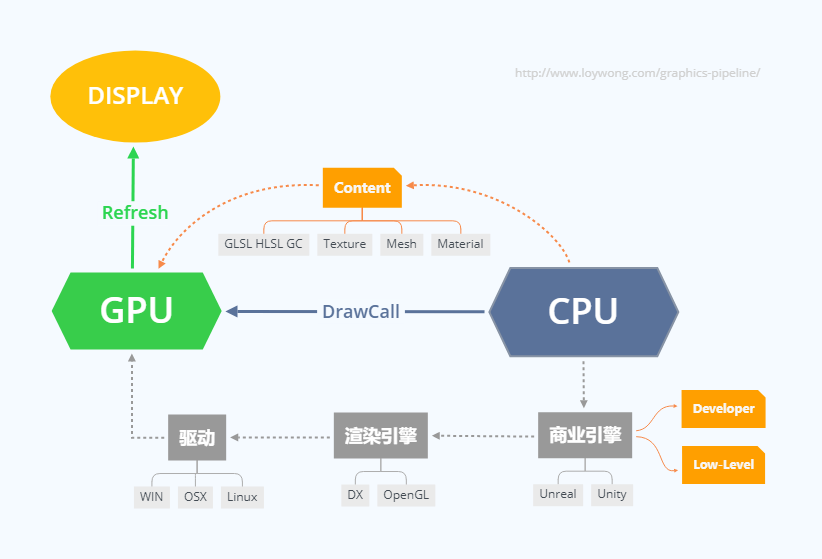
图:计算机图形显示流程
我们从看得见的终端(显示屏幕)出发,来逐步剖析整个过程。
上屏机制
将图形渲染结果(Framebuffer)显示到物理显示屏(LCD)的过程。
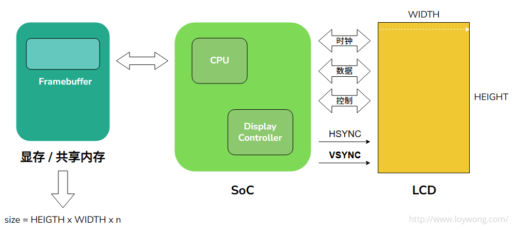
GPU将渲染结果(Framebuffer)存储在显存/共享内存中,CPU通知LCD控制器获取图形数据交给LCD驱动器,并产生必须的LCD控制信号,从而控制和完成图形的显示,翻转,叠加,缩放等一系列复杂的图形显示功能。
Vsync与帧率
首先来体会下不同帧率的画面效果(如下图)。
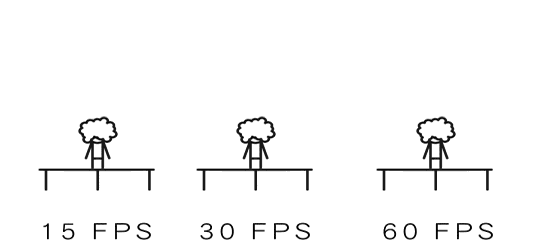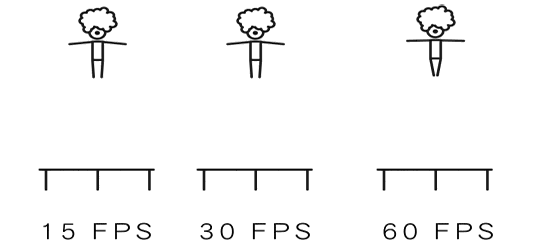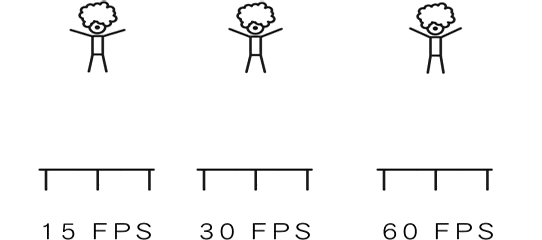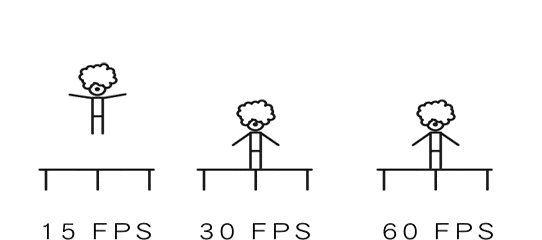
一般一些画面动态演算要求低的手机游戏会采用30FPS,而60FPS对设备性能要求更高,而且功耗会更大,对优化有更高的要求
Vsync是一种通过同步游戏帧率和游戏显示器刷新率来处理屏幕撕裂的方法。
以Unity引擎为例,开启Vsync垂直同步,会限制GPU端的帧数,但CPU可能空跑(可以通过setTargetFrame从CPU端限制提交帧缓冲数据的频率)。特别是现代游戏大量的渲染计算,很可能是GPU Bound,除非CPU需要做一些繁重的逻辑与物理计算(这部分可以多线程机制来优化),当然还有向GPU发送的数据量,其中数据量可以体现为Batch和SetPass Call的数量。值得注意的是Vsync在移动平台上是默认启用的,即便我们在编辑器选项中禁用Vsync,Vsync功能仍会在硬件层面上启用。
CPU和GPU在整个渲染过程中是解耦的,CPU设置好渲染状态,提交渲染数据,调用渲染命令通知GPU执行渲染,GPU不会在渲染过程中回读CPU,性能成本太高。
有3种方法可以降低这个数据量:
- 降低需要渲染的对象的数量,可以同时减少Batch和SetPass Call。
- 降低每个对象需要被渲染的次数,可以减少SetPass Call。
- 将对象合并到更少的批处理当中,可以减少Batch。批处理下面渲染管线的程序阶段还会提到。
当Unity GPU Bound时,Main Thread会处于等待Render Thread的状态。
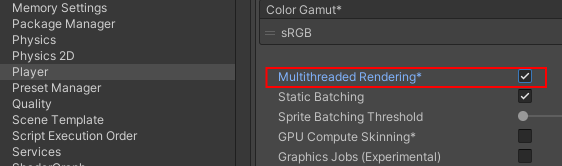
开启多线程渲染时,CPU等待GPU完成工作的耗时会被统计到Gfx.WaitForPresent函数中.
逻辑帧与渲染帧的关系如下图:
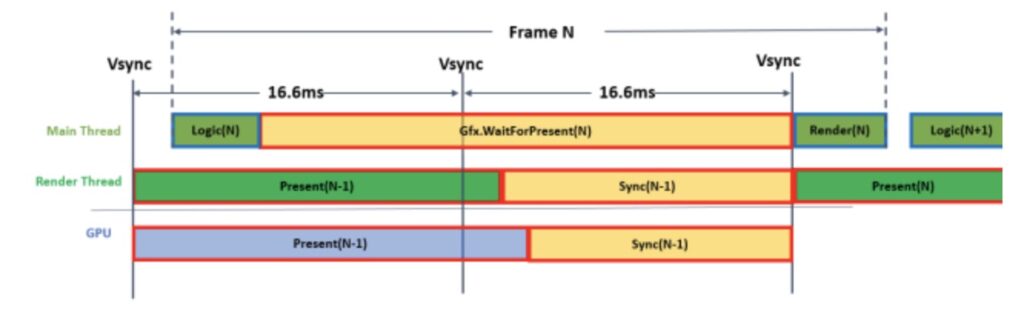
而关闭多线程渲染时这一部分耗时则被主要统计到Graphics.PresentAndSync中。
帧率与刷新率
刷新率,就是显卡将显示信号输出刷新的速度。60赫兹(hertz)就是每秒钟显卡向显示器输出60次信号。高于刷新率的帧数都是无效帧数,而且可能导致画面异常和性能低下。不过如果用户输入Input采用了高采样率,必然就需要高刷新率来反馈给人的视觉系统。
我们知道,现在手机设备开始推出高刷新率了。有些手机需要开白名单(手机厂商),不在白名单的APP,ROM自动会把它降成60FPS。
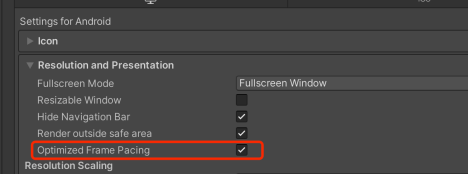
Unity对于高刷新率的手机帧率不稳定的情况下可以开启以下Frame Pacing(Swappy for OpenGL/Vulkan)这项来让帧率更加平滑。
Swap Chain换页机制
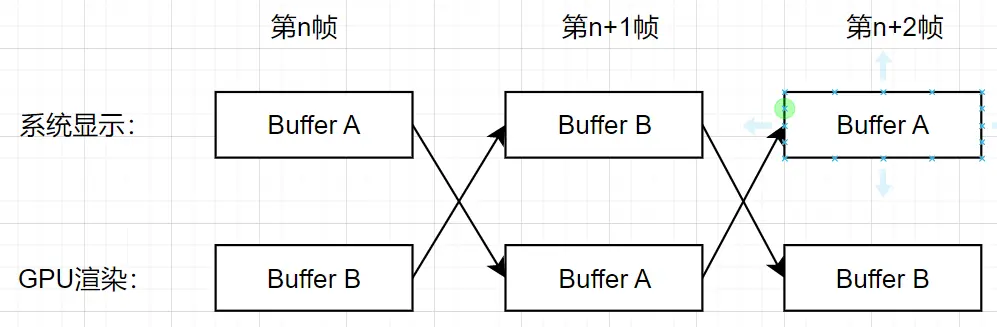
上文提到CPU通知LCD控制器获取图形数据交给LCD驱动器,这里有一个Swap Chain的换页机制。Swap Chain是一系列虚拟帧缓冲区,由GPU(写入)和图形API用于稳定帧速率(一般需要使用多缓冲区的地方都是由于“生产者”和“消费者”供需不一致所造成的,而多缓冲机制可以让速度较慢的一方可以独立的操作数据不至于造成阻塞或丢失)和其他一些功能。
第一个Framebuffer,即Screen Buffer(有时也称为Front Buffer),是呈现到视频卡输出的缓冲区。其余的缓冲区称为后向缓冲区(Back Buffer)。每次显示一个新帧时,交换链中的第一个Back Buffer将取代Screen Buffer,这称为“呈现(Present)”或”交换(Swap)”。
一般采用双缓冲模式:
如果GPU速度更快的话,我们也可以设置Triple Buffer模式:
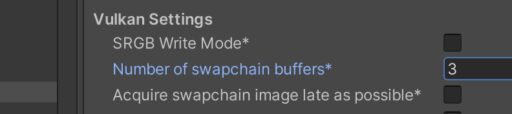
三缓冲机制对于交互式目的应用,如:游戏,来说是更优越的方案。
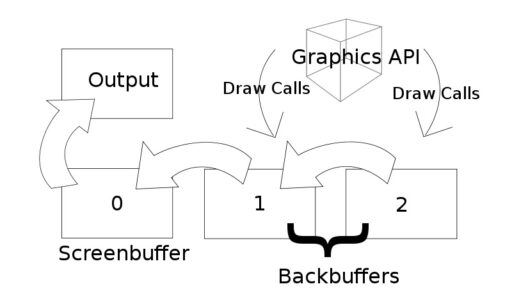
Framebuffer
也叫帧缓冲,是经过图形渲染机制得到的最终结果,可以将其简单理解为屏幕上显示内容对应的缓存。
一个完整的帧缓冲需要满足以下的条件:
- 附加至少一个缓冲(颜色、深度或模板缓冲)
- 至少有一个颜色附件(Attachment)
- 所有的附件都必须是完整的(保留了内存)
- 每个缓冲都应该有相同的样本数。
Framebuffer的结构:
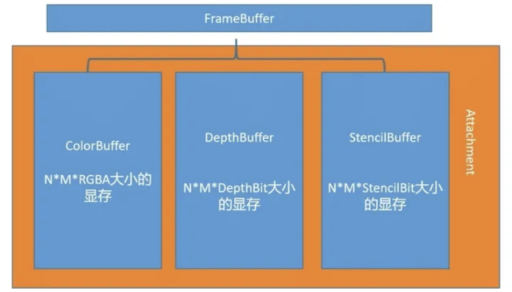
帧缓冲不是指一块现存,而是类似VAO(Vertex Array Object)的一个组织结构,里面包含了很多Attachment(ColorBuffer、DepthBuffer、StencilBuffer),Attachment里会根据不同需求开辟不同的缓存空间。实际上Framebuffer 对象的占用空间非常小。连接到Framebuffer的每个缓冲区可以是Renderbuffer或Texture。
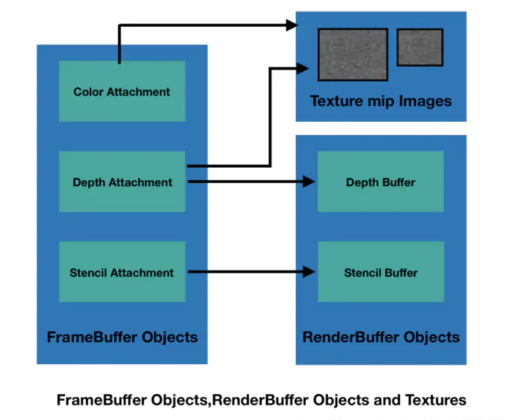
Renderbuffer对象是一个2D图像缓冲区,区别于Texture。它允许将场景直接渲染到渲染缓冲区对象,而不是渲染到纹理对象。 Renderbuffer只是一个数据存储对象,包含可渲染内部格式的单个图像。它用于存储没有相应纹理格式的OpenGL逻辑缓冲区,例如模板或深度缓冲区。
Framebuffer的存储位置可以位于显存,也可以位于内存。比如我们看下PC和Mobile端的硬件结构差异。
PC:GPU和CPU各自有自己的一块内存,GPU有一块专用的显存VRAM,访问起来非常快。
Mobile:GPU和CPU会共享一块内存,GPU有一块on-chip的缓存,不过on-chip缓存放不下一帧FrameBuffer,所以GPU的架构为Tile Based Deferred Renderers(TBDR)